Speech Models and Subjective Speech Quality
The link performance of telephone and closed-user-group speech networks is often described in terms of outage and clipping probability. The aim of this sections is to review some experimental results on the perceptibility of various disturbances to the speech signal.
For details on the network performance we refer to pages on the Erlang models.
Figure: Speech signal amplitude as a function of time.
Speech coding
Contributed by Rakesh Taori, Philips Research, currently with Ericsson.
Voice activity models
Human speech signals contain periods of activity and periods of silence. This fact is for instance exploited in discontinuous transmission (DTX) and digital speech interpolation (DSI). A number of models have been proposed for voice activity, many of which were based on a Markov Chain. A rough model of voice activity is obtained by considering principal talkspurts and principal gaps in the speech as a two-state Markov Chain.
As a refinement, one can distinguish mini-spurts and mini-gaps in each principal talkspurt.
For a fast speech detector, recognizing minigaps and minispurts within principal speechbursts, the voice activity is about 0.36. For a slow speech detector, ignoring short minigaps within principal speech bursts, the voice activity is 0.43.
Stationary of random waveforms
For efficient speech coding, more detailed insight in the statistical behaviour of the speech sounds is required. Typically, a voice waveform can be described as a stationary statistical process during intervals in the order of 20 to 40 ms. This interval is substantially shorter that the duration of a syllable. Consonant-vowel-consonant syllables were analysed by Richards. The following typical durations were observed:
Initial Consonants 70 .. 250 ms, average about 250 ms
Vowels 150 .. 500 ms, average about 250 ms
Final Consonants 100 .. 350 ms, average about 190 ms
Sensitivity of speech to outages
Two types of outages occur: front end clipping at the beginning of speech bursts, thus correlated with the speech process, and Mid Speech Clipping (MSC), thus independent of the speech process.
Front end clipping
For Time Assigned Speech Interpolation (TASI, DSI) on satellite links, freeze-outs are caused by the competition among signals from various subscribers due to statistical multiplexing of multiple voice signals. Statistical multiplexing of voice signals in personal communication networks has been proposed by Goodman et al. in PRMA. Experiments on satellite links revealed that speech clips longer than 50 ms at the beginning of a talkspurt cause perceptible mutilation of initial plosive, stop, fricative and nasal consonants. A typical requirement is that the probability of a clip longer than 50 ms at the beginning of a talkspurt should be less than 2%. The CCIR objective is less than 0.5% FEC
FEC can also be caused by a delays in the voice detector, or if the detector threshold is too high. Voice detector are used among other things for Discontinuous Transmission (DTX), Digital Speech Interpolation (DSI) and echo cancellation.
Mid Speech Clipping
In mobile radio, clips caused by outages of the RF-signal occur at random instants, thus not necessarily at the beginning of talkspurts as in TASI, and are called midspeech burst clipping (MSC). Little or no impairments results for less than 2% MSC with durations less than 4 ms. Clipping durations from 16 to 64 ms produce noticeable quality degradations unless the percentage of speech clipping is less than 0.2% Although the subjective quality degrades for MSC with durations less than 64 ms, the intelligibility is not expected to be seriously degraded. Speech clips larger than 64 ms cause quality degradation as well as reduced intelligibility.
 exercise
exercise
Compare these above MSC durations with average fade durations in a mobile channel.
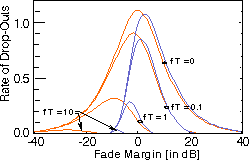
Figure: Rate of dropouts and speech clips (normalized to Doppler spread) in a (frequency nonselective) Rayleigh fading channel
versus fade margin. Orange: single Rayleigh fading interferer, no noise. Violet: Many weak interferers or Gaussian Noise.
Various clip or drop-out durations T, relative to Doppler spread f.
Most short signal outages are experienced as 'clicks'. The clicks cumulatively degrade the circuit, but appear too rapidly to be individually distinguishable. Only longer outages are experienced as temporary 'clipping' or a 'drop-out' of the circuit. The analysis of the probability of outage, no distinction has been made whether this outage would be experienced as a click or as a drop-out. However, Gruber and Strawczynski reported that the subjective rating of outages highly depends on the duration of the speech clips.
A communication system may react in different ways to missing voice segments. In analogue radio, the voice signal will be replaced by noise or crosstalk from other users. In digital systems, error detection schemes recognize outages. During missing blocks of bits, the circuit will be silent (gap silent). Alternatively, the previous voice segment may be repeated to fill in the gap (gaps masked). In some applications, the gaps will be erased and the next correct block will be inserted immediately (gaps closed). This, of course, leads to fluctuating delay in the link. If longer outages occur (more than 64 ms) closing gaps is significantly better than silencing gaps. No significantly different performance is perceived for smaller clips.
Subjective tests results disagree upon the question whether MSC or FEC is less likely to be experience as disturbing.
Speech Quality
Subjective listening tests are usually conducted with a listening panel grading the quality on a scale from 1 to 5, where 5 represents the best speech quality.
In telecommunications, four qualities of speech transmission are distinguished:
- Broadcast quality,
as perceived in FM radio broadcasting with full audio bandwidth (50-15.000 Hz). Source compression schemes proposed for digital broadcasting usually have a bit rate of 64 to 128 kbit/s. The European DAB system uses 192 kbit/s.
- Telephone line quality,
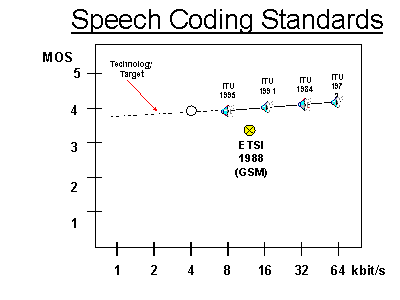
as perceived of the wired public switched telephone services (PSTN). The transmission bandwidth as recommended by the CCITT is 300-3400 Hz with a minimum signal-to-noise ratio of 34 dB. The ISDN standards propose a bit rate of 64 kbit/s using PCM without voice coding. Adaptive PCM can achieve the same performance with 32 kbit/s without significantly increased coding complexity. Efficient but complex compression schemes, developed for digital telephony such as the GSM system, achieve this quality with a bit rate of 9.6 to 16 kbit/s
- communication quality,
having more distortion than the PSTN quality but still highly intelligible. The bandwidth is sometimes reduced to 2000 Hz. Outages may occur frequently.
- synthetic quality,
with machine-like speech quality and usually without a sufficient quality to recognize the speaker. Bit rates can be as low as 300 or 1200 bit/s, using vocoder speech synthesis.
Exercise
A requirement for the U.S. analogue cellular network is that during 90% of the time the instantaneous C/I ratio should be at least 17 dB:
subjective listening tests showed that most subscriber judge the quality good or excellent if the C/I ratio is fixed and above 17 dB. In a certain European network the specification is that during 99% of the time the C/I ratio should be above the FM detection threshold, say C/I > 6 or
10 dB. - Which is the toughest requirement if the channel
is Rayleigh fading and the interference power is stationary?
- What if the interference is a single Rayleigh-fading signal?
- Which criterion do you think is the most appropriate for communication over rapidly fading channels?